Complete Features
These features were completed when this image was assembled
1. Proposed title of this feature request
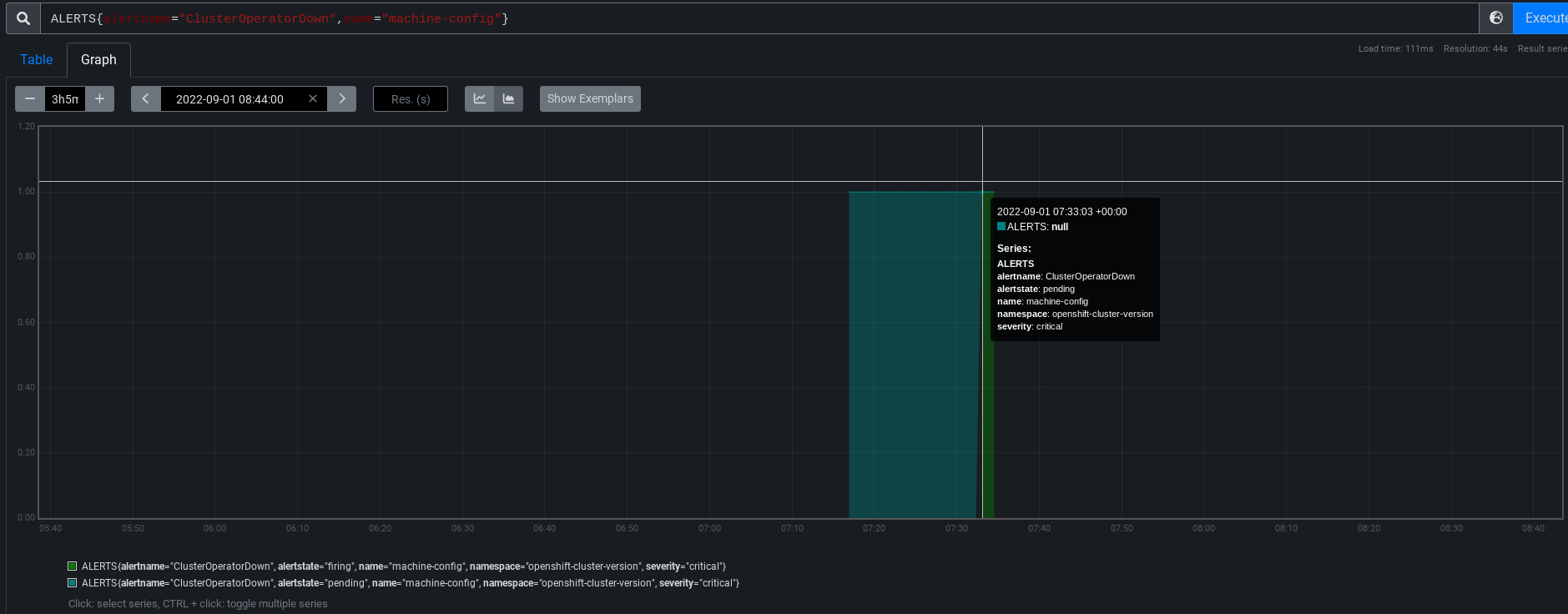
Add runbook_url to alerts in the OCP UI
2. What is the nature and description of the request?
If an alert includes a runbook_url label, then it should appear in the UI for the alert as a link.
3. Why does the customer need this? (List the business requirements here)
Customer can easily reach the alert runbook and be able to address their issues.
4. List any affected packages or components.
As a user, I should be able to configure CSI driver to have a storage topology.
Epic Goal
- Make it possible to disable the console operator at install time, while still having a supported+upgradeable cluster.
Why is this important?
- It's possible to disable console itself using spec.managementState in the console operator config. There is no way to remove the console operator, though. For clusters where an admin wants to completely remove console, we should give the option to disable the console operator as well.
Scenarios
- I'm an administrator who wants to minimize my OpenShift cluster footprint and who does not want the console installed on my cluster
Acceptance Criteria
- It is possible at install time to opt-out of having the console operator installed. Once the cluster comes up, the console operator is not running.
Dependencies (internal and external)
- Composable cluster installation
Previous Work (Optional):
- https://docs.google.com/document/d/1srswUYYHIbKT5PAC5ZuVos9T2rBnf7k0F1WV2zKUTrA/edit#heading=h.mduog8qznwz
- https://docs.google.com/presentation/d/1U2zYAyrNGBooGBuyQME8Xn905RvOPbVv3XFw3stddZw/edit#slide=id.g10555cc0639_0_7
Open questions::
- The console operator manages the downloads deployment as well. Do we disable the downloads deployment? Long term we want to move to CLI manager: https://github.com/openshift/enhancements/blob/6ae78842d4a87593c63274e02ac7a33cc7f296c3/enhancements/oc/cli-manager.md
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
In the console-operator repo we need to add `capability.openshift.io/console` annotation to all the manifests that the operator either contains creates on the fly.
Manifests are currently present in /bindata and /manifest directories.
Here is example of the insights-operator change.
Here is the overall enhancement doc.
Feature Overview
Provide CSI drivers to replace all the intree cloud provider drivers we currently have. These drivers will probably be released as tech preview versions first before being promoted to GA.
Goals
- Framework for rapid creation of CSI drivers for our cloud providers
- CSI driver for AWS EBS
- CSI driver for AWS EFS
- CSI driver for GCP
- CSI driver for Azure
- CSI driver for VMware vSphere
- CSI Driver for Azure Stack
- CSI Driver for Alicloud
- CSI Driver for IBM Cloud
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| Framework for CSI driver | TBD | Yes |
| Drivers should be available to install both in disconnected and connected mode | Yes | |
| Drivers should upgrade from release to release without any impact | Yes | |
| Drivers should be installable via CVO (when in-tree plugin exists) |
Out of Scope
This work will only cover the drivers themselves, it will not include
- enhancements to the CSI API framework
- the migration to said drivers from the the intree drivers
- work for non-cloud provider storage drivers (FC-SAN, iSCSI) being converted to CSI drivers
Background, and strategic fit
In a future Kubernetes release (currently 1.21) intree cloud provider drivers will be deprecated and replaced with CSI equivalents, we need the drivers created so that we continue to support the ecosystems in an appropriate way.
Assumptions
- Storage SIG won't move out the changeover to a later Kubernetes release
Customer Considerations
Customers will need to be able to use the storage they want.
Documentation Considerations
- Target audience: cluster admins
- Updated content: update storage docs to show how to use these drivers (also better expose the capabilities)
This Epic is to track the GA of this feature
Goal
- Make available the Google Cloud File Service via a CSI driver, it is desirable that this implementation has dynamic provisioning
- Without GCP filestore support, we are limited to block / RWO only (GCP PD 4.8 GA)
- Align with what we support on other major public cloud providers.
Why is this important?
- There is a know storage gap with google cloud where only block is supported
- More customers deploying on GCE and asking for file / RWX storage.
Scenarios
- Install the CSI driver
- Remove the CSI Driver
- Dynamically provision a CSI Google File PV*
- Utilise a Google File PV
- Assess optional features such as resize & snapshot
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Customers::
- Telefonica Spain
- Deutsche Bank
Done Checklist
- CI - CI is running, tests are automated and merged.
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
As an OCP user, I want images for GCP Filestore CSI Driver and Operator, so that I can install them on my cluster and utilize GCP Filestore shares.
We need to continue to maintain specific areas within storage, this is to capture that effort and track it across releases.
Goals
- To allow OCP users and cluster admins to detect problems early and with as little interaction with Red Hat as possible.
- When Red Hat is involved, make sure we have all the information we need from the customer, i.e. in metrics / telemetry / must-gather.
- Reduce storage test flakiness so we can spot real bugs in our CI.
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| Telemetry | No | |
| Certification | No | |
| API metrics | No | |
Out of Scope
n/a
Background, and strategic fit
With the expected scale of our customer base, we want to keep load of customer tickets / BZs low
Assumptions
Customer Considerations
Documentation Considerations
- Target audience: internal
- Updated content: none at this time.
Notes
In progress:
- CSI certification flakes a lot. We should fix it before we start testing migration.
- In progress (API server restarts...) https://bugzilla.redhat.com/show_bug.cgi?id=1865857
- Get local-storage-operator and AWS EBS CSI driver operator logs in must-gather (OLM-managed operators are not included there)
- In progress for LSO (must-gather script being included in image) https://bugzilla.redhat.com/show_bug.cgi?id=1756096
- CI flakes:
- Configurable timeouts for e2e tests
- Azure is slow and times out often
- Cinder times out formatting volumes
- AWS resize test times out
- Configurable timeouts for e2e tests
High prio:
- Env. check tool for VMware - users often mis-configure permissions there and blame OpenShift. If we had a tool they could run, it might report better errors.
- Should it be part of the installer?
- Spike exists
- Add / use cloud API call metrics
-
- Helps customers to understand why things are slow
- Helps build cop to understand a flake
- With a post-install step that filters data from Prometheus that’s still running in the CI job.
- Ideas:
- Cloud is throttling X% of API calls longer than Y seconds
- Attach / detach / provisioning / deletion / mount / unmount / resize takes longer than X seconds?
- Capture metrics of operations that are stuck and won’t finish.
- Sweep operation map from executioner???
- Report operation metric into the highest bucket after the bucket threshold (i.e. if 10minutes is the last bucket, report an operation into this bucket after 10 minutes and don’t wait for its completion)?
- Ask the monitoring team?
- Include in CSI drivers too.
- With alerts too
- Report events for cloud issues
- E.g. cloud API reports weird attach/provision error (e.g. due to outage)
- What volume plugins actually users use the most? https://issues.redhat.com/browse/STOR-324
Unsorted
- As the number of storage operators grows, it would be grafana board for storage operators
- CSI driver metrics (from CSI sidecars + the driver itself + its operator?)
- CSI migration?
- Get aggregated logs in cluster
- They're rotated too soon
- No logs from dead / restarted pods
- No tools to combine logs from multiple pods (e.g. 3 controller managers)
- What storage issues customers have? it was 22% of all issues.
- Insufficient docs?
- Probably garbage
- Document basic storage troubleshooting for our supports
- What logs are useful when, what log level to use
- This has been discussed during the GSS weekly team meeting; however, it would be beneficial to have this documented.
- Common vSphere errors, their debugging and fixing.
- Document sig-storage flake handling - not all failed [sig-storage] tests are ours
The End of General support for vSphere 6.7 will be on October 15, 2022. So, vSphere 6.7 will be deprecated for 4.11.
We want to encourage vSphere customers to upgrade to vSphere 7 in OCP 4.11 since VMware is EOLing (general support) for vSphere 6.7 in Oct 2022.
We want the cluster Upgradeable=false + have a strong alert pointing to our docs / requirements.
related slack: https://coreos.slack.com/archives/CH06KMDRV/p1647541493096729
Epic Goal
- Update all images that we ship with OpenShift to the latest upstream releases and libraries.
- Exact content of what needs to be updated will be determined as new images are released upstream, which is not known at the beginning of OCP development work. We don't know what new features will be included and should be tested and documented. Especially new CSI drivers releases may bring new, currently unknown features. We expect that the amount of work will be roughly the same as in the previous releases. Of course, QE or docs can reject an update if it's too close to deadline and/or looks too big.
Traditionally we did these updates as bugfixes, because we did them after the feature freeze (FF). Trying no-feature-freeze in 4.12. We will try to do as much as we can before FF, but we're quite sure something will slip past FF as usual.
Why is this important?
- We want to ship the latest software that contains new features and bugfixes.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update all OCP and kubernetes libraries in storage operators to the appropriate version for OCP release.
This includes (but is not limited to):
- Kubernetes:
- client-go
- controller-runtime
- OCP:
- library-go
- openshift/api
- openshift/client-go
- operator-sdk
Operators:
- aws-ebs-csi-driver-operator
- aws-efs-csi-driver-operator
- azure-disk-csi-driver-operator
- azure-file-csi-driver-operator
- openstack-cinder-csi-driver-operator
- gcp-pd-csi-driver-operator
- gcp-filestore-csi-driver-operator
- manila-csi-driver-operator
- ovirt-csi-driver-operator
- vmware-vsphere-csi-driver-operator
- alibaba-disk-csi-driver-operator
- ibm-vpc-block-csi-driver-operator
- csi-driver-shared-resource-operator
- cluster-storage-operator
- csi-snapshot-controller-operator
- local-storage-operator
- vsphere-problem-detector
- https://github.com/openshift/alibaba-disk-csi-driver-operator/pull/36
- https://github.com/openshift/aws-ebs-csi-driver-operator/pull/161
- https://github.com/openshift/azure-disk-csi-driver-operator/pull/53
- https://github.com/openshift/azure-file-csi-driver-operator/pull/37
- https://github.com/openshift/cluster-csi-snapshot-controller-operator/pull/128
- https://github.com/openshift/cluster-storage-operator/pull/317
- https://github.com/openshift/csi-driver-manila-operator/pull/155
- https://github.com/openshift/csi-driver-shared-resource-operator/pull/57
- https://github.com/openshift/gcp-pd-csi-driver-operator/pull/52
- https://github.com/openshift/ibm-vpc-block-csi-driver-operator/pull/42
- https://github.com/openshift/openstack-cinder-csi-driver-operator/pull/92
- https://github.com/openshift/ovirt-csi-driver-operator/pull/107
- https://github.com/openshift/vmware-vsphere-csi-driver-operator/pull/109
- https://github.com/openshift/vsphere-problem-detector/pull/88
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
This includes ibm-vpc-node-label-updater!
(Using separate cards for each driver because these updates can be more complicated)
Update all CSI sidecars to the latest upstream release.
- external-attacher
- external-provisioner
- external-resizer
- external-snapshotter
- node-driver-registrar
- livenessprobe
This includes update of VolumeSnapshot CRDs in https://github.com/openshift/cluster-csi-snapshot-controller-operator/tree/master/assets
There is a new driver release 5.0.0 since the last rebase that includes snapshot support:
https://github.com/kubernetes-sigs/ibm-vpc-block-csi-driver/releases/tag/v5.0.0
Rebase the driver on v5.0.0 and update the deployments in ibm-vpc-block-csi-driver-operator.
There are no corresponding changes in ibm-vpc-node-label-updater since the last rebase.
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Epic Goal
- Enable the migration from a storage intree driver to a CSI based driver with minimal impact to the end user, applications and cluster
- These migrations would include, but are not limited to:
- CSI driver for AWS EBS
- CSI driver for GCP
- CSI driver for Azure (file and disk)
- CSI driver for VMware vSphere
Why is this important?
- OpenShift needs to maintain it's ability to enable PVCs and PVs of the main storage types
- CSI Migration is getting close to GA, we need to have the feature fully tested and enabled in OpenShift
- Upstream intree drivers are being deprecated to make way for the CSI drivers prior to intree driver removal
Scenarios
- User initiated move to from intree to CSI driver
- Upgrade initiated move from intree to CSI driver
- Upgrade from EUS to EUS
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This Epic tracks the GA of this feature
Epic Goal
- Provide the ability to move, as seamlessly as possible from the intree GCE driver to it's CSI equivalent
- https://github.com/kubernetes/enhancements/issues/1488
Why is this important?
- OpenShift needs to maintain it's ability to enable PVCs and PVs of the main storage types
- CSI Migration is getting close to GA, we need to have the feature fully tested and enabled in OpenShift
- Upstream intree drivers are being deprecated to make way for the CSI drivers prior to intree driver removal
Scenarios
- User initiated move to from intree to CSI driver
- Upgrade initiated move from intree to CSI driver
- Upgrade from EUS to EUS
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
On new installations, we should make the StorageClass created by the CSI operator the default one.
However, we shouldn't do that on an upgrade scenario. The main reason is that users might have set a different quota on the CSI driver Storage Class.
Exit criteria:
- New clusters get the CSI Storage Class as the default one.
- Existing clusters don't get their default Storage Classes changed.
On new installations, we should make the StorageClass created by the CSI operator the default one.
However, we shouldn't do that on an upgrade scenario. The main reason is that users might have set a different quota on the CSI driver Storage Class.
Exit criteria:
- New clusters get the CSI Storage Class as the default one.
- Existing clusters don't get their default Storage Classes changed.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Rebase OpenShift components to k8s v1.24
Why is this important?
- Rebasing ensures components work with the upcoming release of Kubernetes
- Address tech debt related to upstream deprecations and removals.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- k8s 1.24 release
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Rebase openshift-controller-manager to k8s 1.24
Feature Overview
- As an infrastructure owner, I want a repeatable method to quickly deploy the initial OpenShift cluster.
- As an infrastructure owner, I want to install the first (management, hub, “cluster 0”) cluster to manage other (standalone, hub, spoke, hub of hubs) clusters.
Goals
- Enable customers and partners to successfully deploy a single “first” cluster in disconnected, on-premises settings
Requirements
4.11 MVP Requirements
- Customers and partners needs to be able to download the installer
- Enable customers and partners to deploy a single “first” cluster (cluster 0) using single node, compact, or highly available topologies in disconnected, on-premises settings
- Installer must support advanced network settings such as static IP assignments, VLANs and NIC bonding for on-premises metal use cases, as well as DHCP and PXE provisioning environments.
- Installer needs to support automation, including integration with third-party deployment tools, as well as user-driven deployments.
- In the MVP automation has higher priority than interactive, user-driven deployments.
- For bare metal deployments, we cannot assume that users will provide us the credentials to manage hosts via their BMCs.
- Installer should prioritize support for platforms None, baremetal, and VMware.
- The installer will focus on a single version of OpenShift, and a different build artifact will be produced for each different version.
- The installer must not depend on a connected registry; however, the installer can optionally use a previously mirrored registry within the disconnected environment.
Use Cases
- As a Telco partner engineer (Site Engineer, Specialist, Field Engineer), I want to deploy an OpenShift cluster in production with limited or no additional hardware and don’t intend to deploy more OpenShift clusters [Isolated edge experience].
- As a Enterprise infrastructure owner, I want to manage the lifecycle of multiple clusters in 1 or more sites by first installing the first (management, hub, “cluster 0”) cluster to manage other (standalone, hub, spoke, hub of hubs) clusters [Cluster before your cluster].
- As a Partner, I want to package OpenShift for large scale and/or distributed topology with my own software and/or hardware solution.
- As a large enterprise customer or Service Provider, I want to install a “HyperShift Tugboat” OpenShift cluster in order to offer a hosted OpenShift control plane at scale to my consumers (DevOps Engineers, tenants) that allows for fleet-level provisioning for low CAPEX and OPEX, much like AKS or GKE [Hypershift].
- As a new, novice to intermediate user (Enterprise Admin/Consumer, Telco Partner integrator, RH Solution Architect), I want to quickly deploy a small OpenShift cluster for Poc/Demo/Research purposes.
Questions to answer…
Out of Scope
Out of scope use cases (that are part of the Kubeframe/factory project):
- As a Partner (OEMs, ISVs), I want to install and pre-configure OpenShift with my hardware/software in my disconnected factory, while allowing further (minimal) reconfiguration of a subset of capabilities later at a different site by different set of users (end customer) [Embedded OpenShift].
- As an Infrastructure Admin at an Enterprise customer with multiple remote sites, I want to pre-provision OpenShift centrally prior to shipping and activating the clusters in remote sites.
Background, and strategic fit
- This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- The user has only access to the target nodes that will form the cluster and will boot them with the image presented locally via a USB stick. This scenario is common in sites with restricted access such as government infra where only users with security clearance can interact with the installation, where software is allowed to enter in the premises (in a USB, DVD, SD card, etc.) but never allowed to come back out. Users can't enter supporting devices such as laptops or phones.
- The user has access to the target nodes remotely to their BMCs (e.g. iDrac, iLo) and can map an image as virtual media from their computer. This scenario is common in data centers where the customer provides network access to the BMCs of the target nodes.
- We cannot assume that we will have access to a computer to run an installer or installer helper software.
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
References
Epic Goal
As an OpenShift infrastructure owner, I want to deploy a cluster zero with RHACM or MCE and have the required components installed when the installation is completed
Why is this important?
BILLI makes it easier to deploy a cluster zero. BILLI users know at installation time what the purpose of their cluster is when they plan the installation. Day-2 steps are necessary to install operators and users, especially when automating installations, want to finish the installation flow when their required components are installed.
Acceptance Criteria
- A user can provide MCE manifests and have it installed without additional manual steps after the installation is completed
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a customer, I want to be able to:
- Install MCE with the agent-installer
so that I can achieve
- create an MCE hub with my openshift install
Acceptance Criteria:
Description of criteria:
- Upstream documentation including examples of the extra manifests needed
- Unit tests that include MCE extra manifests
- Ability to install MCE using agent-installer is tested
- Point 3
(optional) Out of Scope:
We are only allowing the user to provide extra manifests to install MCE at this time. We are not adding an option to "install mce" on the command line (or UI)
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a customer, I want to be able to:
- Install MCE with the agent-installer
so that I can achieve
- create an MCE hub with my openshift install
Acceptance Criteria:
Description of criteria:
- Upstream documentation including examples of the extra manifests needed
- Unit tests that include MCE extra manifests
- Ability to install MCE using agent-installer is tested
- Point 3
(optional) Out of Scope:
We are only allowing the user to provide extra manifests to install MCE at this time. We are not adding an option to "install mce" on the command line (or UI)
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Set the ClusterDeployment CRD to deploy OpenShift in FIPS mode and make sure that after deployment the cluster is set in that mode
In order to install FIPS compliant clusters, we need to make sure that installconfig + agentoconfig based deployments take into account the FIPS config in installconfig.
This task is about passing the config to agentclusterinstall so it makes it into the iso. Once there, AGENT-374 will give it to assisted service
Epic Goal
As a OpenShift infrastructure owner, I want to deploy OpenShift clusters with dual-stack IPv4/IPv6
As a OpenShift infrastructure owner, I want to deploy OpenShift clusters with single-stack IPv6
Why is this important?
IPv6 and dual-stack clusters are requested often by customers, especially from Telco customers. Working with dual-stack clusters is a requirement for many but also a transition into a single-stack IPv6 clusters, which for some of our users is the final destination.
Acceptance Criteria
- Agent-based installer can deploy IPv6 clusters
- Agent-based installer can deploy dual-stack clusters
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Previous Work
Karim's work proving how agent-based can deploy IPv6: IPv6 deploy with agent based installer]
Done Checklist * CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>|
For dual-stack installations the agent-cluster-install.yaml must have both an IPv4 and IPv6 subnet in the networkking.MachineNetwork or assisted-service will throw an error. This field is in InstallConfig but it must be added to agent-cluster-install in its Generate().
For IPv4 and IPv6 installs, setting up the MachineNetwork is not needed but it also does not cause problems if its set, so it should be fine to set it all times.
Epic Goal
- Rebase cluster autoscaler on top of Kubernetes 1.25
Why is this important?
- Need to pick up latest upstream changes
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story
As a user I would like to see all the events that the autoscaler creates, even duplicates. Having the CAO set this flag will allow me to continue to see these events.
Background
We have carried a patch for the autoscaler that would enable the duplication of events. This patch can now be dropped because the upstream added a flag for this behavior in https://github.com/kubernetes/autoscaler/pull/4921
Steps
- add the --record-duplicated-events flag to all autoscaler deployments from the CAO
Stakeholders
- openshift eng
Definition of Done
- autoscaler continues to work as expected and produces events for everything
- Docs
- this does not require documentation as it preserves existing behavior and provides no interface for user interaction
- Testing
- current tests should continue to pass
Feature Overview
Add GA support for deploying OpenShift to IBM Public Cloud
Goals
Complete the existing gaps to make OpenShift on IBM Cloud VPC (Next Gen2) General Available
Requirements
- OpenShift can be deployed into an existing network provided by the user (https://issues.redhat.com/browse/CORS-2263)
- OpenShift can be deployed with both Public and Private publish options (https://issues.redhat.com/browse/SPLAT-731)
Optional requirements
- OpenShift can be deployed using Mint mode and STS for cloud provider credentials (future release, tbd)
- OpenShift can be deployed in disconnected mode https://issues.redhat.com/browse/SPLAT-737)
- OpenShift on IBM Cloud supports User Provisioned Infrastructure (UPI) deployment method (future release, 4.14?)
This epic tracks the changes needed to the ingress operator to support IBM DNS Services for private clusters.
Epic Goal
- Enable installation of private clusters on IBM Cloud. This epic will track associated work.
Why is this important?
- This is required MVP functionality to achieve GA.
Scenarios
- Install a private cluster on IBM Cloud.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Background and Goal
Currently in OpenShift we do not support distributing hotfix packages to cluster nodes. In time-sensitive situations, a RHEL hotfix package can be the quickest route to resolving an issue.
Acceptance Criteria
- Under guidance from Red Hat CEE, customers can deploy RHEL hotfix packages to MachineConfigPools.
- Customers can easily remove the hotfix when the underlying RHCOS image incorporates the fix.
Before we ship OCP CoreOS layering in https://issues.redhat.com/browse/MCO-165 we need to switch the format of what is currently `machine-os-content` to be the new base image.
The overall plan is:
- Publish the new base image as `rhel-coreos-8` in the release image
- Also publish the new extensions container (https://github.com/openshift/os/pull/763) as `rhel-coreos-8-extensions`
- Teach the MCO to use this without also involving layering/build controller
- Delete old `machine-os-content`
As a OCP CoreOS layering developer, having telemetry data about number of cluster using osImageURL will help understand how broadly this feature is getting used and improve accordingly.
Acceptance Criteria:
- Cluster using Custom osImageURL is available via telemetry
After https://github.com/openshift/os/pull/763 is in the release image, teach the MCO how to use it. This is basically:
- Schedule the extensions container as a kubernetes service (just serves a yum repo via http)
- Change the MCD to write a file into `/etc/yum.repos.d/machine-config-extensions.repo` that consumes it instead of what it does now in pulling RPMs from the mounted container filesystem
Goal: Control plane nodes in the cluster can be scaled up or down, lost and recovered, with no more importance or special procedure than that of a data plane node.
Problem: There is a lengthy special procedure to recover from a failed control plane node (or majority of nodes) and to add new control plane nodes.
Why is this important: Increased operational simplicity and scale flexibility of the cluster’s control plane deployment.
See slack working group: #wg-ctrl-plane-resize
Background
We recently finished working on the CPMS main controller. We now need a way to generate the CPMS object for a cluster based on its current state.
We want a new controller that based on the cluster state generates a CPMS object and creates it against the API of the cluster. The CPMS object that will be created will have the `.spec.state` field set to `Inactive`, meaning that the main CPMS controller won't do any modification to the cluster based on that configuration until the user has reviewed/modified it and activated it by setting it to `Active`.
To catch changes in the cluster state the CPMS generator controller will keep watching the state and perform CPMS object regenerations checking if the object needs updating. If that's the case the generator will delete and recreate the CPMS object. This will constantly happen while the CPMS state is set to `Inactive`. As soon as the user activates it (sets `.spec.state` to `Active`). The generator controller will stop processing and its logic will become a no-op.
For now the generator controller will only be able to generate config for AWS clusters.
We should make sure to include envtest based testing to give us confidence when making changes to the code in the future.
Steps
- Add the CPMS generator controller logic
- Write up a suite of tests to validate the behaviour of the controller
Stakeholders
- Cluster Infra
- Service Delivery
Definition of Done
- Test coverage for the tool is >80%
- Docs
- N/A
- Testing
- N/A
Why?
- Decouple control and data plane.
- Customers do not pay Red Hat more to run HyperShift control planes and supporting infrastructure than Standalone control planes and supporting infrastructure.
- Improve security
- Shift credentials out of cluster that support the operation of core platform vs workload
- Improve cost
- Allow a user to toggle what they don’t need.
- Ensure a smooth path to scale to 0 workers and upgrade with 0 workers.
Assumption
- A customer will be able to associate a cluster as “Infrastructure only”
- E.g. one option: management cluster has role=master, and role=infra nodes only, control planes are packed on role=infra nodes
- OR the entire cluster is labeled infrastructure , and node roles are ignored.
- Anything that runs on a master node by default in Standalone that is present in HyperShift MUST be hosted and not run on a customer worker node.
Doc: https://docs.google.com/document/d/1sXCaRt3PE0iFmq7ei0Yb1svqzY9bygR5IprjgioRkjc/edit
Overview
Customers do not pay Red Hat more to run HyperShift control planes and supporting infrastructure than Standalone control planes and supporting infrastructure.
Assumption
- A customer will be able to associate a cluster as “Infrastructure only”
- E.g. one option: management cluster has role=master, and role=infra nodes only, control planes are packed on role=infra nodes
- OR the entire cluster is labeled infrastructure, and node roles are ignored.
- Anything that runs on a master node by default in Standalone that is present in HyperShift MUST be hosted and not run on a customer worker node.
DoD
cluster-snapshot-controller-operator is running on the CP.
More information here: https://docs.google.com/document/d/1sXCaRt3PE0iFmq7ei0Yb1svqzY9bygR5IprjgioRkjc/edit
As OpenShift developer I want cluster-csi-snapshot-controller-operator to use existing controllers in library-go, so I don’t need to maintain yet another code that does the same thing as library-go.
- Check and remove manifests/03_configmap.yaml, it does not seem to be useful.
- Check and remove manifests/03_service.yaml, it does not seem to be useful (at least now).
- Use DeploymentController from library-go to sync Deployments.
- Get rid of common/ package? It does not seem to be useful.
- Use StaticResourceController for static content, including the snapshot CRDs.
Note: if this refactoring introduces any new conditions, we must make sure that 4.11 snapshot controller clears them to support downgrade! This will need 4.11 BZ + z-stream update!
Similarly, if some conditions become obsolete / not managed by any controller, they must be cleared by 4.12 operator.
Exit criteria:
- The operator code is smaller.
- No regressions in standalone OCP.
- Upgrade/downgrade from/to standalone OCP 4.11 works.
As HyperShift Cluster Instance Admin, I want to run cluster-csi-snapshot-controller-operator in the management cluster, so the guest cluster runs just my applications.
- Add a new cmdline option for the guest cluster kubeconfig file location
- Parse both kubeconfigs:
-
- One from projected service account, which leads to the management cluster.
-
- Second from the new cmdline option introduced above. This one leads to the guest cluster.
- Move creation of manifests/08_webhook_service.yaml from CVO to the operator - it needs to be created in the management cluster.
- Tag manifests of objects that should not be deployed by CVO in HyperShift by
- Only on HyperShift:
-
- When interacting with Kubernetes API, carefully choose the right kubeconfig to watch / create / update objects in the right cluster.
-
- Replace namespaces in all Deployments and other objects that are created in the management cluster. They must be created in the same namespace as the operator.
-
- Don’t create operand’s PodDisruptionBudget?
-
- Update ValidationWebhookConfiguration to point directly to URL exposed by manifests/08_webhook_service.yaml instead of a Service. The Service is not available in the guest cluster.
-
- Pass only the guest kubeconfig to the operands (both the webhook and csi-snapshot-controller).
-
- Update unit tests to handle two kube clients.
Exit criteria:
- cluster-csi-snapshot-controller-operator runs in the management cluster in HyperShift
- csi-snapshot-controller runs in the management cluster in HyperShift
- It is possible to take & restore volume snapshot in the guest cluster.
- No regressions in standalone OCP.
Overview
Customers do not pay Red Hat more to run HyperShift control planes and supporting infrastructure than Standalone control planes and supporting infrastructure.
Assumption
- A customer will be able to associate a cluster as “Infrastructure only”
- E.g. one option: management cluster has role=master, and role=infra nodes only, control planes are packed on role=infra nodes
- OR the entire cluster is labeled infrastructure, and node roles are ignored.
- Anything that runs on a master node by default in Standalone that is present in HyperShift MUST be hosted and not run on a customer worker node.
DoD
Run cluster-storage-operator (CSO) + AWS EBS CSI driver operator + AWS EBS CSI driver control-plane Pods in the management cluster, run the driver DaemonSet in the hosted cluster.
More information here: https://docs.google.com/document/d/1sXCaRt3PE0iFmq7ei0Yb1svqzY9bygR5IprjgioRkjc/edit
As OCP support engineer I want the same guest cluster storage-related objects in output of "hypershift dump cluster --dump-guest-cluster" as in "oc adm must-gather ", so I can debug storage issues easily.
must-gather collects: storageclasses persistentvolumes volumeattachments csidrivers csinodes volumesnapshotclasses volumesnapshotcontents
hypershift collects none of this, the relevant code is here: https://github.com/openshift/hypershift/blob/bcfade6676f3c344b48144de9e7a36f9b40d3330/cmd/cluster/core/dump.go#L276
Exit criteria:
- verify that hypershift dump cluster --dump-guest-cluster has storage objects from the guest cluster.
As HyperShift Cluster Instance Admin, I want to run cluster-storage-operator (CSO) in the management cluster, so the guest cluster runs just my applications.
- Add a new cmdline option for the guest cluster kubeconfig file location
- Parse both kubeconfigs:
- One from projected service account, which leads to the management cluster.
- Second from the new cmdline option introduced above. This one leads to the guest cluster.
- Tag manifests of objects that should not be deployed by CVO in HyperShift
- Only on HyperShift:
-
- When interacting with Kubernetes API, carefully choose the right kubeconfig to watch / create / update objects in the right cluster.
-
- Replace namespaces in all Deployments and other objects that are created in the management cluster. They must be created in the same namespace as the operator.
-
- Pass only the guest kubeconfig to the operands (AWS EBS CSI driver operator).
Exit criteria:
- CSO and AWS EBS CSI driver operator runs in the management cluster in HyperShift
- Storage works in the guest cluster.
- No regressions in standalone OCP.
As HyperShift Cluster Instance Admin, I want to run AWS EBS CSI driver operator + control plane of the CSI driver in the management cluster, so the guest cluster runs just my applications.
- Add a new cmdline option for the guest cluster kubeconfig file location
- Parse both kubeconfigs:
- One from projected service account, which leads to the management cluster.
- Second from the new cmdline option introduced above. This one leads to the guest cluster.
- Only on HyperShift:
-
- When interacting with Kubernetes API, carefully choose the right kubeconfig to watch / create / update objects in the right cluster.
-
- Replace namespaces in all Deployments and other objects that are created in the management cluster. They must be created in the same namespace as the operator.
-
- Pass only the guest kubeconfig to the operand (control-plane Deployment of the CSI driver).
Exit criteria:
- Control plane Deployment of AWS EBS CSI driver runs in the management cluster in HyperShift.
- Storage works in the guest cluster.
- No regressions in standalone OCP.
Epic Goal
- To improve debug-ability of ovn-k in hypershift
- To verify the stability of of ovn-k in hypershift
- To introduce a EgressIP reach-ability check that will work in hypershift
Why is this important?
- ovn-k is supposed to be GA in 4.12. We need to make sure it is stable, we know the limitations and we are able to debug it similar to the self hosted cluster.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
Dependencies (internal and external)
- This will need consultation with the people working on HyperShift
Previous Work (Optional):
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
CNCC was moved to the management cluster and it should use proxy settings defined for the management cluster.
OC mirror is GA product as of Openshift 4.11 .
The goal of this feature is to solve any future customer request for new features or capabilities in OC mirror
Epic Goal
- Mirror to mirror operations and custom mirroring flows required by IBM CloudPak catalog management
Why is this important?
- IBM needs additional customization around the actual mirroring of images to enable CloudPaks to fully adopt OLM-style operator packaging and catalog management
- IBM CloudPaks introduce additional compute architectures, increasing the download volume by 2/3rds to day, we need the ability to effectively filter non-required image versions of OLM operator catalogs during filtering for other customers that only require a single or a subset of the available image architectures
- IBM CloudPaks regularly run on older OCP versions like 4.8 which require additional work to be able to read the mirrored catalog produced by oc mirror
Scenarios
- Customers can use the oc utility and delegate the actual image mirror step to another tool
- Customers can mirror between disconnected registries using the oc utility
- The oc utility supports filtering manifest lists in the context of multi-arch images according to the sparse manifest list proposal in the distribution spec
Acceptance Criteria
- Customers can use the oc utility to mirror between two different air-gapped environments
- Customers can specify the desired computer architectures and oc mirror will create sparse manifest lists in the target registry as a result
Dependencies (internal and external)
- Sparse Manifest List Support in Red Hat Quay (PROJQUAY-3114)
Previous Work:
Related Work:
- Proposed title of this feature request:
Update ETCD datastore encryption to use AES-GCM instead of AES-CBC
2. What is the nature and description of the request?
The current ETCD datastore encryption solution uses the aes-cbc cipher. This cipher is now considered "weak" and is susceptible to padding oracle attack. Upstream recommends using the AES-GCM cipher. AES-GCM will require automation to rotate secrets for every 200k writes.
The cipher used is hard coded.
3. Why is this needed? (List the business requirements here).
Security conscious customers will not accept the presence and use of weak ciphers in an OpenShift cluster. Continuing to use the AES-CBC cipher will create friction in sales and, for existing customers, may result in OpenShift being blocked from being deployed in production.
4. List any affected packages or components.
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
The Kube APIserver is used to set the encryption of data stored in etcd. See https://docs.openshift.com/container-platform/4.11/security/encrypting-etcd.html
Today with OpenShift 4.11 or earlier, only aescbc is allowed as the encryption field type.
RFE-3095 is asking that aesgcm (which is an updated and more recent type) be supported. Furthermore RFE-3338 is asking for more customizability which brings us to how we have implemented cipher customzation with tlsSecurityProfile. See https://docs.openshift.com/container-platform/4.11/security/tls-security-profiles.html
Why is this important? (mandatory)
AES-CBC is considered as a weak cipher
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
The new aesgcm encryption provider was added in 4.13 as techpreview, but as part of https://issues.redhat.com/browse/API-1509, the feature needs to be GA in OCP 4.13.
Goal: Control plane nodes in the cluster can be scaled up or down, lost and recovered, with no more importance or special procedure than that of a data plane node.
Problem: There is a lengthy special procedure to recover from a failed control plane node (or majority of nodes) and to add new control plane nodes.
Why is this important: Increased operational simplicity and scale flexibility of the cluster’s control plane deployment.
See slack working group: #wg-ctrl-plane-resize
Epic Goal
- Resolve the outstanding technical debt from the ControlPlaneMachineSet project
Why is this important?
- We need to make sure the project is tested, documented and maintained going forward
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Background
Now that we have a CPMS generator controller, we need to document how the user will interact with the CPMS to activate it.
Steps
- Document how to review the generated CPMS object
- Document how to fix the most common cluster state inconsistencies to make the generated CPMS object a no-op on the cluster
- Document how to Activate the CPMS object and what that means
- Update the CPMS enhancement regarding the installation.
Stakeholders
- Cluster Infra
- Service Delivery
Definition of Done
- Docs are merged
- Docs
- N/A
- Testing
- N/A
Background
Not every platform needs to support failure domains, for example baremetal.
In order to support generic platforms, we could introduce a generic providerConfig abstraction that can handle the case when the failureDomains is empty.
In this case, we never manipulate the providerSpec anyway so there's no need to have a platform specific providerConfig abstraction.
Steps
- Create a generic providerConfig abstraction
- Write tests for the generic providerConfig abstraction
- Integrate this so that we use the generic abstraction when there are no failure domains
- Test on a platform that doesn't support failure domains, eg vSphere
Stakeholders
- Cluster Infra
- Platforms who aren't AWS, GCP, Azure
Definition of Done
- We can support generic platforms
- Docs
- Announce single zone support for any platform
- Testing
- Manual testing against single zone and other platforms such as vSphere
Feature Overview
RHEL CoreOS should be updated to RHEL 9.2 sources to take advantage of newer features, hardware support, and performance improvements.
Requirements
- RHEL 9.x sources for RHCOS builds starting with OCP 4.13 and RHEL 9.2.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
9.2 Preview via LayeringNo longer necessary assuming we stay the course of going all in on 9.2
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
PROBLEM
We would like to improve our signal for RHEL9 readiness by increasing internal engineering engagement and external partner engagement on our community OpehShift offering, OKD.
PROPOSAL
Adding OKD to run on SCOS (a CentOS stream for CoreOS) brings the community offering closer to what a partner or an internal engineering team might expect on OCP.
ACCEPTANCE CRITERIA
Image has been switched/included:
DEPENDENCIES
The SCOS build payload.
RELATED RESOURCES
OKD+SCOS proposal: https://docs.google.com/presentation/d/1_Xa9Z4tSqB7U2No7WA0KXb3lDIngNaQpS504ZLrCmg8/edit#slide=id.p
OKD+SCOS work draft: https://docs.google.com/document/d/1cuWOXhATexNLWGKLjaOcVF4V95JJjP1E3UmQ2kDVzsA/edit
Acceptance Criteria
A stable OKD on SCOS is built and available to the community sprintly.
This comes up when installing ipi-on-aws on arm64 with the custom payload build at quay.io/aleskandrox/okd-release:4.12.0-0.okd-centos9-full-rebuild-arm64 that is using scos as machine-content-os image
```
[root@ip-10-0-135-176 core]# crictl logs c483c92e118d8
2022-08-11T12:19:39+00:00 [cnibincopy] FATAL ERROR: Unsupported OS ID=scos
```
The probable fix has to land on https://github.com/openshift/cluster-network-operator/blob/master/bindata/network/multus/multus.yaml#L41-L53
Overview
HyperShift came to life to serve multiple goals, some are main near-term, some are secondary that serve well long-term.
Main Goals for hosted control planes (HyperShift)
- Optimize OpenShift for Cost/footprint/ which improves our competitive stance against the *KSes
- Establish separation of concerns which makes it more resilient for SRE to manage their workload clusters (be it security, configuration management, etc).
- Simplify and enhance multi-cluster management experience especially since multi-cluster is becoming an industry need nowadays.
Secondary Goals
HyperShift opens up doors to penetrate the market. HyperShift enables true hybrid (CP and Workers decoupled, mixed IaaS, mixed Arch,...). An architecture that opens up more options to target new opportunities in the cloud space. For more details on this one check: Hosted Control Planes (aka HyperShift) Strategy [Live Document]
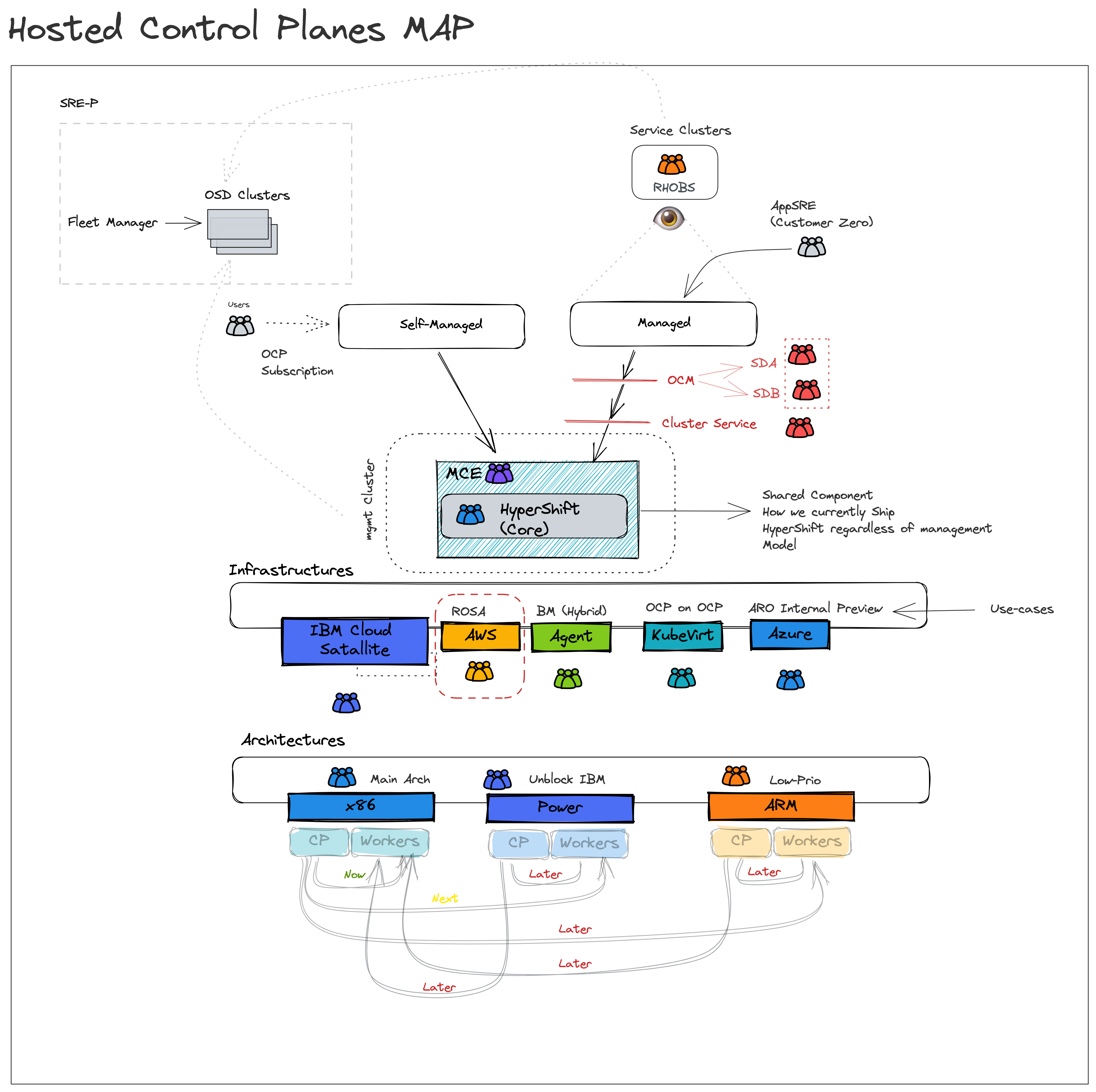
Hosted Control Planes (HyperShift) Map
To bring hosted control planes to our customers, we need the means to ship it. Today MCE is how HyperShift shipped, and installed so that customers can use it. There are two main customers for hosted-control-planes:
- Self-managed: In that case, Red Hat would provide hosted control planes as a service that is managed and SREed by the customer for their tenants (hence “self”-managed). In this management model, our external customers are the direct consumers of the multi-cluster control plane as a servie. Once MCE is installed, they can start to self-service dedicated control planes.
- Managed: This is OpenShift as a managed service, today we only “manage” the CP, and share the responsibility for other system components, more info here. To reduce management costs incurred by service delivery organizations which translates to operating profit (by reducing variable costs per control-plane), as well as to improve user experience, lower platform overhead (allow customers to focus mostly on writing applications and not concern themselves with infrastructure artifacts), and improve the cluster provisioning experience. HyperShift is shipped via MCE, and delivered to Red Hat managed SREs (same consumption route). However, for managed services, additional tooling needs to be refactored to support the new provisioning path. Furthermore, unlike self-managed where customers are free to bring their own observability stack, Red Hat managed SREs need to observe the managed fleet to ensure compliance with SLOs/SLIs/…
If you have noticed, MCE is the delivery mechanism for both management models. The difference between managed and self-managed is the consumer persona. For self-managed, it's the customer SRE for managed its the RH SRE.
High-level Requirements
For us to ship HyperShift in the product (as hosted control planes) in either management model, there is a necessary readiness checklist that we need to satisfy. Below are the high-level requirements needed before GA:
- Hosted control planes fits well with our multi-cluster story (with MCE)
- Hosted control planes APIs are stable for consumption
- Customers are not paying for control planes/infra components.
- Hosted control planes has an HA and a DR story
- Hosted control planes is in parity with top-level add-on operators
- Hosted control planes reports metrics on usage/adoption
- Hosted control planes is observable
- HyperShift as a backend to managed services is fully unblocked.
Please also have a look at our What are we missing in Core HyperShift for GA Readiness? doc.
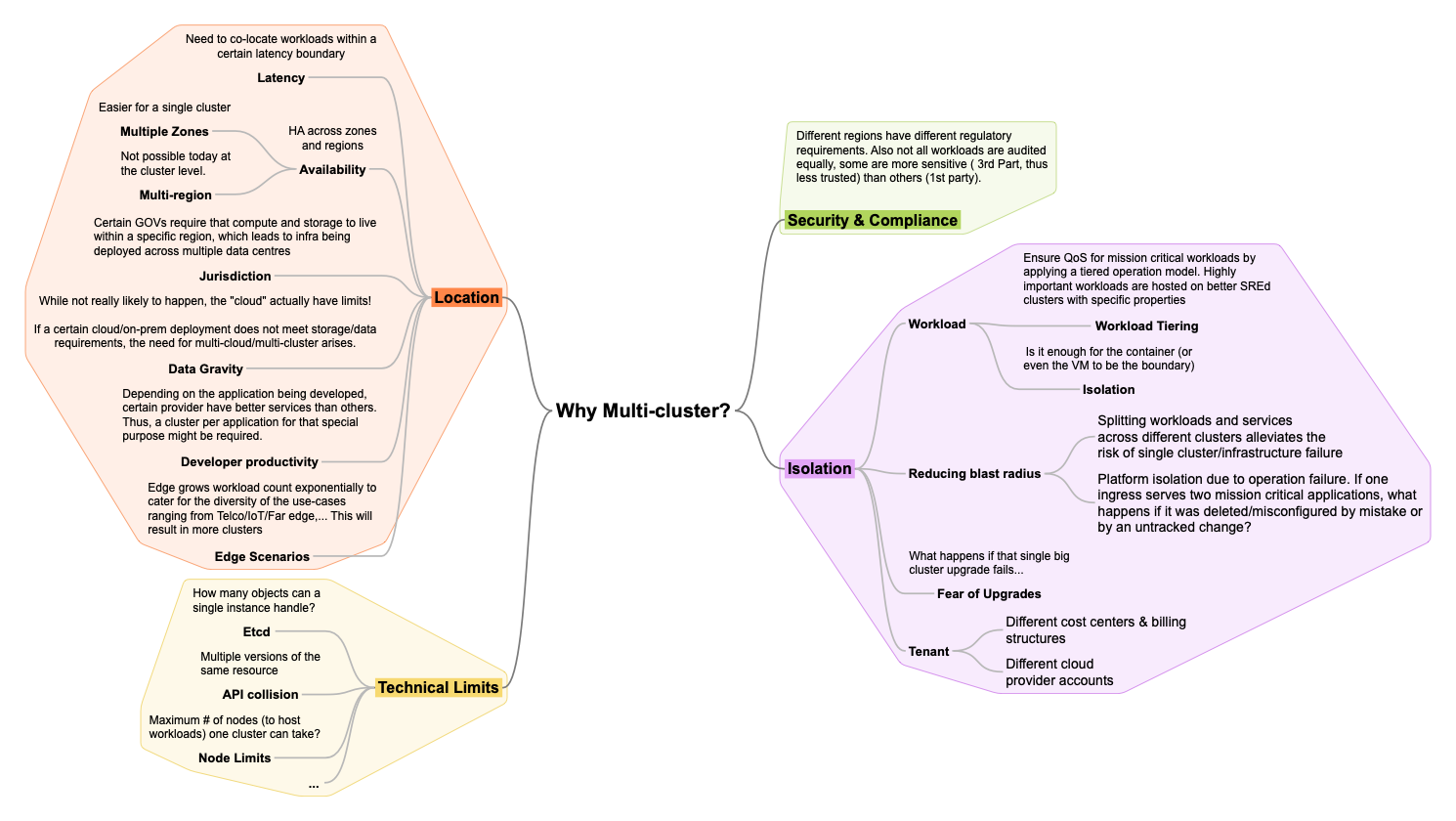
Hosted control planes fits well with our multi-cluster story
Multi-cluster is becoming an industry need today not because this is where trend is going but because it’s the only viable path today to solve for many of our customer’s use-cases. Below is some reasoning why multi-cluster is a NEED:
As a result, multi-cluster management is a defining category in the market where Red Hat plays a key role. Today Red Hat solves for multi-cluster via RHACM and MCE. The goal is to simplify fleet management complexity by providing a single pane of glass to observe, secure, police, govern, configure a fleet. I.e., the operand is no longer one cluster but a set, a fleet of clusters.
HyperShift logically centralized architecture, as well as native separation of concerns and superior cluster lifecyle management experience, makes it a great fit as the foundation of our multi-cluster management story.
Thus the following stories are important for HyperShift:
- When lifecycling OpenShift clusters (for any OpenShift form factor) on any of the supported providers from MCE/ACM/OCM/CLI as a Cluster Service Consumer (RH managed SRE, or self-manage SRE/admin):
- I want to be able to use a consistent UI so I can manage and operate (observe, govern,...) a fleet of clusters.
- I want to specify HA constraints (e.g., deploy my clusters in different regions) while ensuring acceptable QoS (e.g., latency boundaries) to ensure/reduce any potential downtime for my workloads.
- When operating OpenShift clusters (for any OpenShift form factor) on any of the supported provider from MCE/ACM/OCM/CLI as a Cluster Service Consumer (RH managed SRE, or self-manage SRE/admin):
- I want to be able to backup any critical data so I am able to restore them in case of hosting service cluster (management cluster) failure.
Refs:
- Agenda/Notes - HyperShift/ACM UX Sync
- https://coreos.slack.com/archives/C02TPGYJ6NN/p1657117542026339
- AWS UI and Agent Provisioning UI mocks
Hosted control planes APIs are stable for consumption.
HyperShift is the core engine that will be used to provide hosted control-planes for consumption in managed and self-managed.
Main user story: When life cycling clusters as a cluster service consumer via HyperShift core APIs, I want to use a stable/backward compatible API that is less susceptible to future changes so I can provide availability guarantees.
Ref: What are we missing in Core HyperShift for GA Readiness?
Customers are not paying for control planes/infra components.
Customers do not pay Red Hat more to run HyperShift control planes and supporting infrastructure than Standalone control planes and supporting infrastructure.
Assumptions:
- A customer will be able to associate a cluster as “Infrastructure only”
- E.g. one option: management cluster has role=master, and role=infra nodes only, control planes are packed on role=infra nodes
- OR the entire cluster is labeled infrastructure , and node roles are ignored.
- Anything that runs on a master node by default in Standalone that is present in HyperShift MUST be hosted and not run on a customer worker node.
HyperShift - proposed cuts from data plane
HyperShift has an HA and a DR story
When operating OpenShift clusters (for any OpenShift form factor) from MCE/ACM/OCM/CLI as a Cluster Service Consumer (RH managed SRE, or self-manage SRE/admin) I want to be able to migrate CPs from one hosting service cluster to another:
- as means for disaster recovery in the case of total failure
- so that scaling pressures on a management cluster can be mitigated or a management cluster can be decommissioned.
More information:
Hosted control planes reports metrics on usage/adoption
To understand usage patterns and inform our decision making for the product. We need to be able to measure adoption and assess usage.
See Hosted Control Planes (aka HyperShift) Strategy [Live Document]
Hosted control plane is observable
Whether it's managed or self-managed, it’s pertinent to report health metrics to be able to create meaningful Service Level Objectives (SLOs), alert of failure to meet our availability guarantees. This is especially important for our managed services path.
HyperShift is in parity with top-level add-on operators
https://issues.redhat.com/browse/OCPPLAN-8901
Unblock HyperShift as a backend to managed services
HyperShift for managed services is a strategic company goal as it improves usability, feature, and cost competitiveness against other managed solutions, and because managed services/consumption-based cloud services is where we see the market growing (customers are looking to delegate platform overhead).
We should make sure our SD milestones are unblocked by the core team.
Note
This feature reflects HyperShift core readiness to be consumed. When all related EPICs and stories in this EPIC are complete HyperShift can be considered ready to be consumed in GA form. This does not describe a date but rather the readiness of core HyperShift to be consumed in GA form NOT the GA itself.
- GA date for self-managed will be factoring in other inputs such as adoption, customer interest/commitment, and other factors.
- GA dates for ROSA-HyperShift are on track, tracked in milestones M1-7 (have a look at https://issues.redhat.com/browse/OCPPLAN-5771)
Epic Goal*
The goal is to split client certificate trust chains from the global Hypershift root CA.
Why is this important? (mandatory)
This is important to:
- assure a workload can be run on any kind of OCP flavor
- reduce the blast radius in case of a sensitive material leak
- separate trust to allow more granular control over client certificate authentication
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- I would like to be able to run my workloads on any OpenShift-like platform.
My workloads allow components to authenticate using client certificates based
on a trust bundle that I am able to retrieve from the cluster.
- I don't want my users to have access to any CA bundle that would allow them
to trust a random certificate from the cluster for client certificate authentication.
Dependencies (internal and external) (mandatory)
Hypershift team needs to provide us with code reviews and merge the changes we are to deliver
Contributing Teams(and contacts) (mandatory)
- Development - OpenShift Auth, Hypershift
- Documentation -OpenShift Auth Docs team
- QE - OpenShift Auth QE
- PX - I have no idea what PX is
- Others - others
Acceptance Criteria (optional)
The serviceaccount CA bundle automatically injected to all pods cannot be used to authenticate any client certificate generated by the control-plane.
Drawbacks or Risk (optional)
Risk: there is a throbbing time pressure as this should be delivered before first stable Hypershift release
Done - Checklist (mandatory)
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
AUTH-311 introduced an enhancement. Implement the signer separation described there.